Copy pasting advantages
While playing on Grasshopper, we often need to perform the same operations but with different input data. Therefore, it is convenient to just copy paste an entire group.
Quick and simple, this solution seems to be convenient. And then we copy paste this group as many times as we have different inputs.
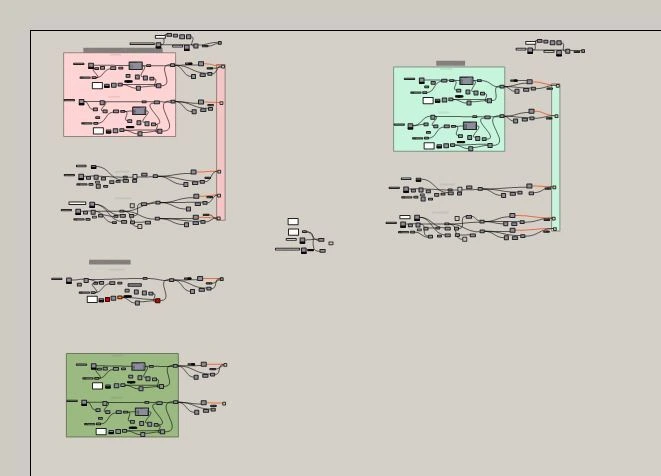
Does it look like one of your script?
Surely, your first definitions should look like this! A repetitive pattern, the same blocks all arranged in columns and... just a huge Explode Tree or List Items to plug the different inputs. It's fine, you were learning Grasshopper. At that time, it was okay to do that.
However, if your definitions still look like this one, it might be a good time to dive deep in the data management of Grasshopper.
Why should you avoid copy-pasting large group of components?
The truth: copy-pasting is a scalability killer. Everytime you have an additional set of input data, you must copy-paste the group and plug the new input manually.
You might tell me "It's already faster than doing everything manually all the time!". True. But why did you start Grasshopper or even computational design? To automate your tasks as much as possible!
Aiming to be a computational designer means to reach the peak of automation: scalability of your automation in any circumstances.
Data Tree for scalability
To solve this copy-pasting issue, data trees are what you're looking for.
A quick recap on Data Tree
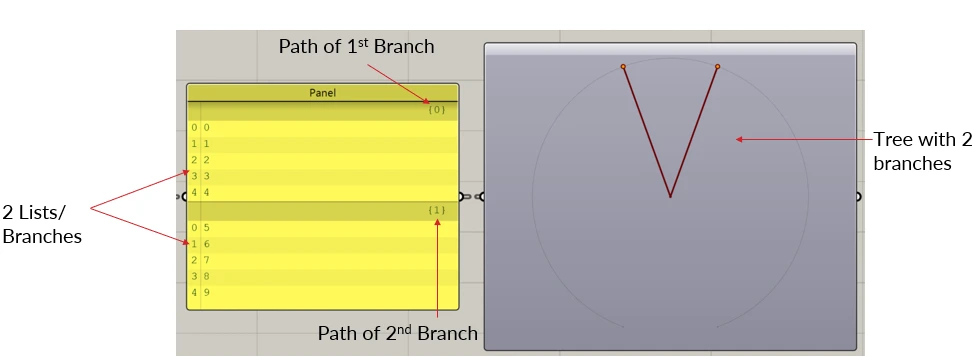
As a reminder, a Data Tree is basically a List of Lists. We can also say that a List is a Tree with one branch.
A Data Tree has branches and each branch has a path (basically a name).
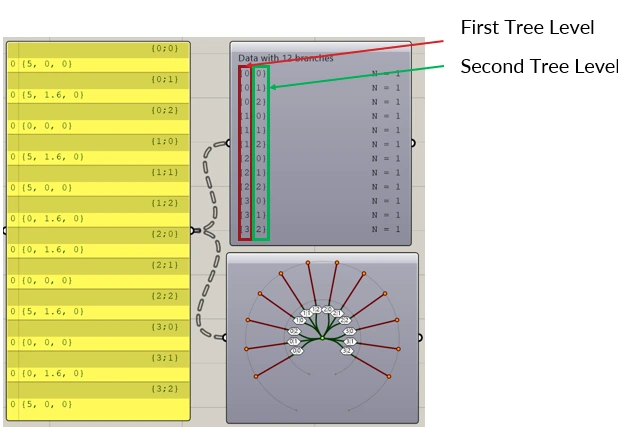
A Data Tree also has a depth, this is the number of levels in the tree. It is important to note that only the last level contains the items. The lower levels are used to organize your data, in other words to give meaning to your data.
If you're not comfortable with Data Trees, PatchWork designed a high-quality training on data management fundamentals: Grasshopper Data Tree.
How to apply the Data Trees properly to scale my script?
My best advice is to have a two layer tree. The first layer represents the different input data sets you were plugging in to each group. While the second layer (and above) should be similar to the unique set you were plugging in individually.
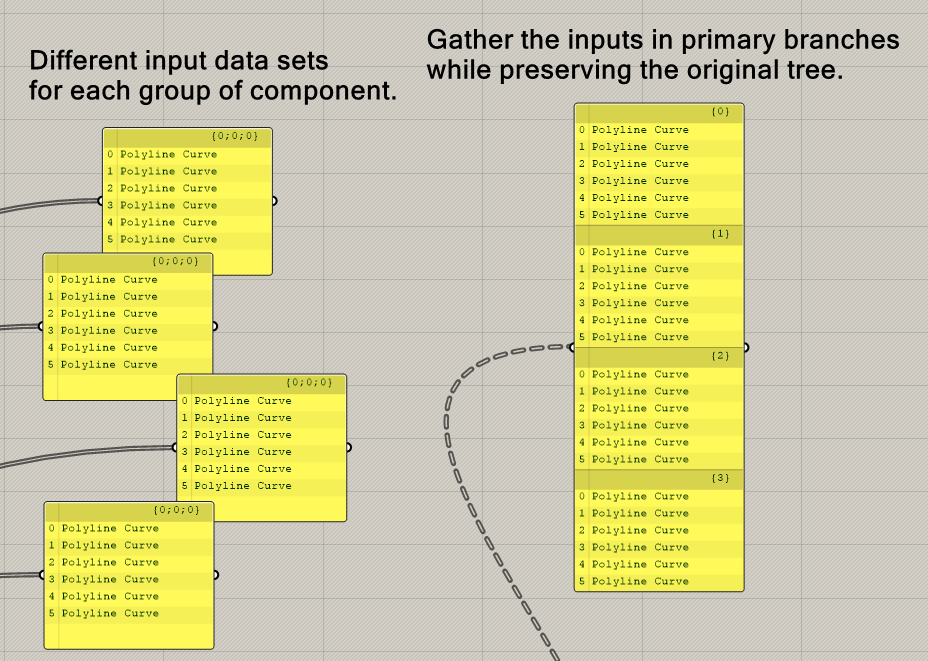
By doing this, it doesn't matter whether your input has 5 primary branches or 1000. It will always be able to treat these branches separately.
One more data set to add? Your script is able to handle.
One data set less? Still handling it perfectly.
And no action is required on your side! Isn't it magical? Manage your data tree properly and you will be able to push your automation to a whole new level.